
RabbitMQ
RabbitMQ
这两天学习RabbitMQ,还是一知半解,现在想想根本不知道这玩意是干啥的(刘少还没讲应用)。别说应用了,这玩意课上简单的demo敲完我都一脸懵😵,所以还是好好梳理一下概念和demo的流程(这里说是很值钱💴)。
简介
在说RabbitMQ前,先和我们说了AMQP(高级消息队列协议),一个提供统一消息服务的应用层标准高级消息队列协议,是应用层协议的一个开放标准,为面向消息的中间件设计。基于此协议的客户端与消息中间件可传递消息,并不受客户端/中间件不同产品,不同的开发语言等条件的限制。
这一大堆的介绍是一句听不懂,不过RabbitMQ其实就是一个实现了AMQP的开源的消息中间件,使用高性能的Erlang编写的。
上面有两个概念刚听到的时候不是太理解,消息队列和消息中间件。我直接百度一下,万能的百度没有你我可咋办呀🧡💛💚💚💙💙💜🤎💖
什么是消息队列?
大佬就是不一样,这种娓娓道来的感觉是真的让我佩服。以后再看见消息队列心里就默念异步、削峰、解耦(异步、削峰、解耦;异步、削峰、解耦…背他个100遍先😠)。
消息队列简单的说就是把消息放在队列中,其本身就是一个中间件,那什么是消息、什么是队列呢?
消息就是我们需要传递的数据,而队列就是一种先进先出的数据结构。简单关联一下我们做的项目,有些数据我们接收后需要传递,传递到某些功能的队列中,根据队列中不同功能的执行顺序依次执行(还是比较模糊😵)
实际上消息队列和消息中间件是一回事。从实现上来说,它是一个消息的“队列”,把它放到系统里,它就成为了一个中间件。简单说消息队列是概念,消息中间件就是实现概念的产出。
PS:
provider
消息的生产者,就是投递消息的程序consumer
消息的消费者,就是接收消息的程序
RabbitMQ简单demo
我们使用RabbitMQ前需要在Linux上进行下载
1 | 查找镜像 |
在Linux上安装完docker后按照步骤一顿复制粘贴就行😂,最后返回一段看不懂的数据就可以
http://192.168.145.128:15672/#/
返回成功后进入网页如果能成功进入我们就完成了第一步(其中192.168…这个地址要是你Linux的端口号)

接着我们开始进行配置
配置文件
在pom.xml中我们要导入RabbitMQ的依赖,还要注意Spring Boot版本号,这里用的是2.5.7,太高的版本可能会出现问题。
1 | <!--RabbitMQ依赖--> |
application.properties
1 | # 项目名(可以自定义) |
当我们创建RabbitMQ容器时docker run -d --hostname chenziyang --name rabbitmq -e RABBITMQ_USER=guest -e RABBITMQ_PASS=guest -p 15672:15672 -p 5672:5672 c20中15672是提供给web使用,而5672提供个idea使用,账号和密码在创建容器时也已经指定。
Java代码
消息队列配置类QueueConfig
1 | /** |
创建队列方法中Queue就是声明创建一个名字为queueName的队列,之后发送方provider将信息放到队列中,接收方consumer从队列中读取消息。
消息生产者类Sender
1 | /** |
上面的类就是消息的生产者,还是老样子,先说一说里面不明白的地方吧。
首先,我们给这个类一个注解
@Component,虽然大概知道是标记这个类是什么类型,但是具体的还是不太清楚(都是曾经欠下的帐😭),然后就是AmqpTemplate,对于template之前好像也使用过,但是根本不明白他的用途(好像说这个类似于springMVC的内容)最后还有个好像是新的注释@ValueAmqpTemplate
指定一组基本的 AMQP 操作。提供同步发送和接收方法。
convertAndSend(Object)andreceiveAndConvert()方法允许您发送和接收 POJO 对象。实现应该委托给一个实例MessageConverter来执行与 AMQP byte[] 有效负载类型之间的转换。上面是官方API的解释,Template本意也是模板的意思,那这个就可以大体理解了,后面再详细看看。
@Component
@Component就是spring中的一个注解,作用就是实现bean的注入
消息接收者类Receive
1 |
|
通过Application启动在RabbitMQ网页上可以看队列的信息说明启动成功。
测试类
1 |
|
运行测试类,在控制台中就可以看到输出的信息
其实这样看看也不是太难(毕竟是第一个例子)
- 消息队列配置类(QueueConfig)中新建了一个名为
hello-queue的queue队列,这个名字是我们在application.properties中自定义的属性,在QueueConfig中通过@Value注解通过key值获取。- 在消息生产者类(Sender)类中,通过消息队列模板
AmqpTemplate中的方法将要发送的信息打包好发送出去- 消息接收者类通过
@RabbitListener注解监听队列名,接收消息- 消息在测试类中,注入消息生产者类,输入要传递的消息
感觉直接去梳理流程太慢了,跟不上课程了,还是先把其中的原理搞清楚,抽空再把流程写出来,还能复习一下。(这两天的东西都没有完成,不能拆东墙补西墙,合理分配时间💪)
RabbitMQ工作原理
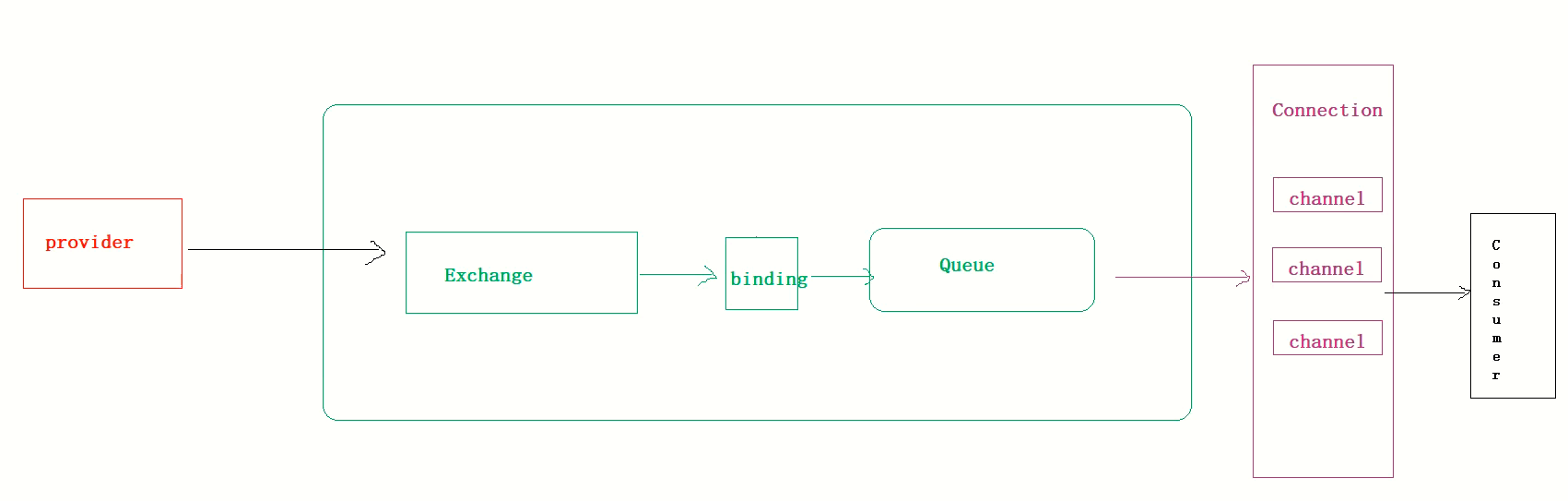
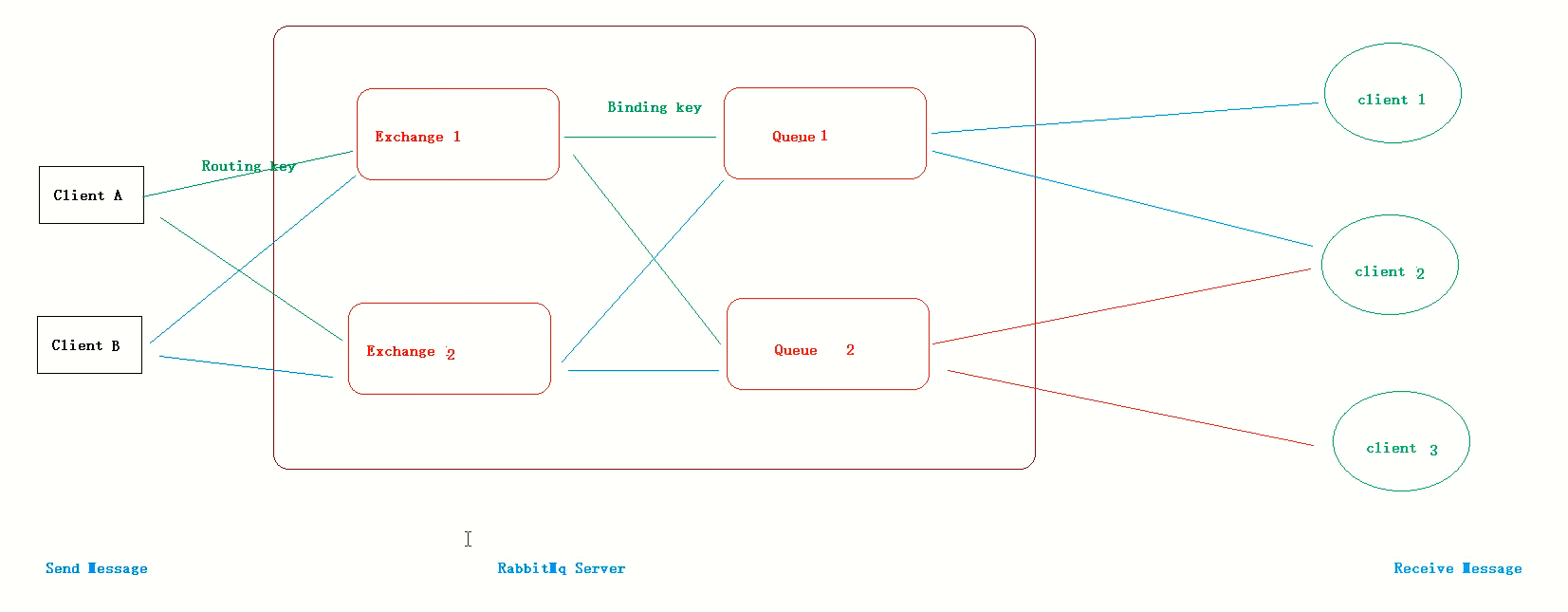
上面两张图片就是RabbitMQ的工作原理图图片上的概念,我们要稍微梳理一下
名词解释
| 解释 | |
|---|---|
| Message | 消息 消息是不具名的 它是由消息头和主体组成,消息体不透明 消息头是由一系列的属性组成routing-key(路由键)、优先权、消息的存储(永久的) |
| provider (Publisher) | 消息的生产者,就是投递消息的程序 |
| consumer | 消息的消费者,就是接收消息的程序 |
| Exchange | 交换器 用来接收生产者发送的消息,将消息路由给服务器中的队列 三种类型: 1.订阅与发布 direct 2.广播 fanout 3.主题,规则匹配 topic |
| Binding | 绑定消息队列和交换器之间的关联 |
| Queue | 消息队列 用来保存消息最终发给消费者 |
| Routing-key | 路由键 RabbitMQ决定消息投递到哪个队列的规则 |
| Connection | 链接,rabbit和服务器之间建立的tcp 链接 |
| Channel | 信道 TCP中的虚拟链接,TCP就被打开,就会创建AMQP,无论是发布、接收、订阅等都是通过信道完成的 |
| Broker | 消息队列服务的实体 |
上面大部分的概念理解起来还是不困难的,最困扰我的还是两个key和Exchange交换器,不知道具体是有什么用处,我们还是先捋一下RabbitMQ这些名词的意思吧。参考文章
RabbitMQ其实就是一个实现了AMQP的开源的消息中间件,再通俗点就是RabbitMQ是消息队列的一种实现。所以我们要围绕队列(queue)来阐述不明白的RabbitMQ中各种名词的含义。
Exchange:我们需要让queue都接收到生产者发送的消息时,不可能给每个queue都发送一次消息,而且这样做肯定会造成资源的浪费。所以我们需要想出一种解决方法,给RabbitMQ一个规则,让它自己去解析需要给哪个队列发送消息。Exchange就是干这件事的,这里的规则就对应上面Exchange常用的三种类型。
RabbitMQ为什么需要信道? 为什么不是TCP 直接通道?
- TCP的创建和销毁开销特别大,创建需要3次握手,销毁需要4次分手!
- 如果不用信道,应用程序就会以tcp方式进行链接,高峰时段每秒数以万计造成巨大的资源浪费,而且操作系统每秒钟处理TCP的数量是有限的,就会产生性能的瓶颈。
- 信道的原理是一个线程一条通道,多个线程多条通道同用一条TCP链接,一条TCP链接可以容纳无限的信道,请求量过大不会称为性能瓶颈。
交换器Exchange
我们上面说了Exchange是一种规则,向队列queue发送消息的一种规则。那么为什么我们需要 Exchange 而不是直接将消息发送至队列呢?
在实际应用中我们只需要定义好 Exchange 的路由策略,而生产者则不需要关心消息会发送到哪个 Queue 或被哪些 Consumer 消费。在这种模式下生产者只面向 Exchange 发布消息,消费者只面向 Queue 消费消息,Exchange 定义了消息路由到 Queue 的规则,将各个层面的消息传递隔离开,使每一层只需要关心自己面向的下一层,降低了整体的耦合度。
理解 Exchange
Exchange 收到消息时,他是如何知道需要发送至哪些 Queue 呢?这里就需要了解 Binding 和 RoutingKey 的概念:
Binding 表示 Exchange 与 Queue 之间的关系,我们也可以简单的认为队列对该交换机上的消息感兴趣,绑定可以附带一个额外的参数 RoutingKey。Exchange 就是根据这个 RoutingKey 和当前 Exchange 所有绑定的 Binding 做匹配,如果满足匹配,就往 Exchange 所绑定的 Queue 发送消息,这样就解决了我们向 RabbitMQ 发送一次消息,可以分发到不同的 Queue。RoutingKey 的意义依赖于交换机的类型。
下面就来了解一下 Exchange 的三种主要类型:Fanout、Direct 和 Topic。
发布与订阅 direct
也叫完全匹配,如图
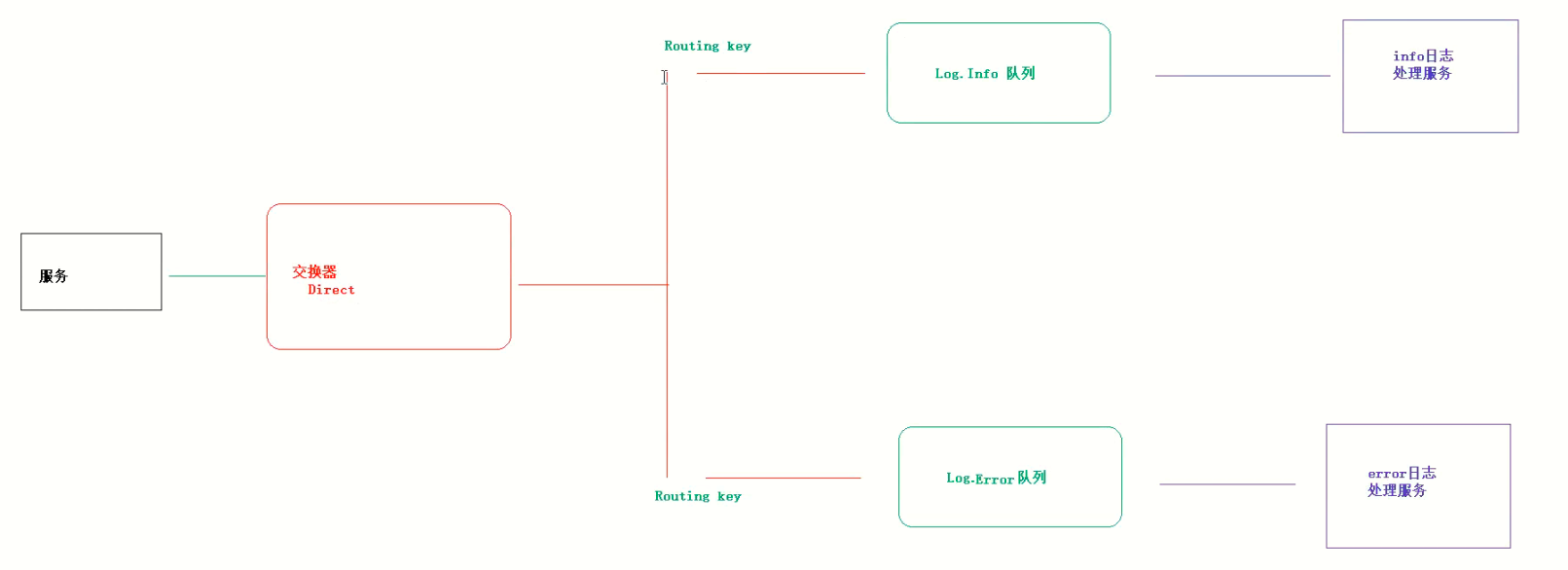
Direct Exchange 是 RabbitMQ 默认的 Exchange,完全根据 routing-key来路由消息。设置 交换器(Exchange) 和队列(Queue)的Binding时需指定routing-key(一般为 queueName),发消息时也指定一样的 routing-key,消息就会被路由到对应的Queue。从别名完全匹配也可以看出来direct的特点,就是精确匹配,routing-key和对应的路由一一匹配。
应用场景
现在我们考虑只把重要的日志消息写入磁盘文件,例如只把 Error 级别的日志发送给负责记录写入磁盘文件的 Queue。这种场景下我们可以使用指定的 RoutingKey(例如 error)将写入磁盘文件的 Queue 绑定到 Direct Exchange 上。
广播 fanout
Fanout Exchange 会忽略 RoutingKey 的设置,直接将 Message 广播到所有绑定的 Queue 中。
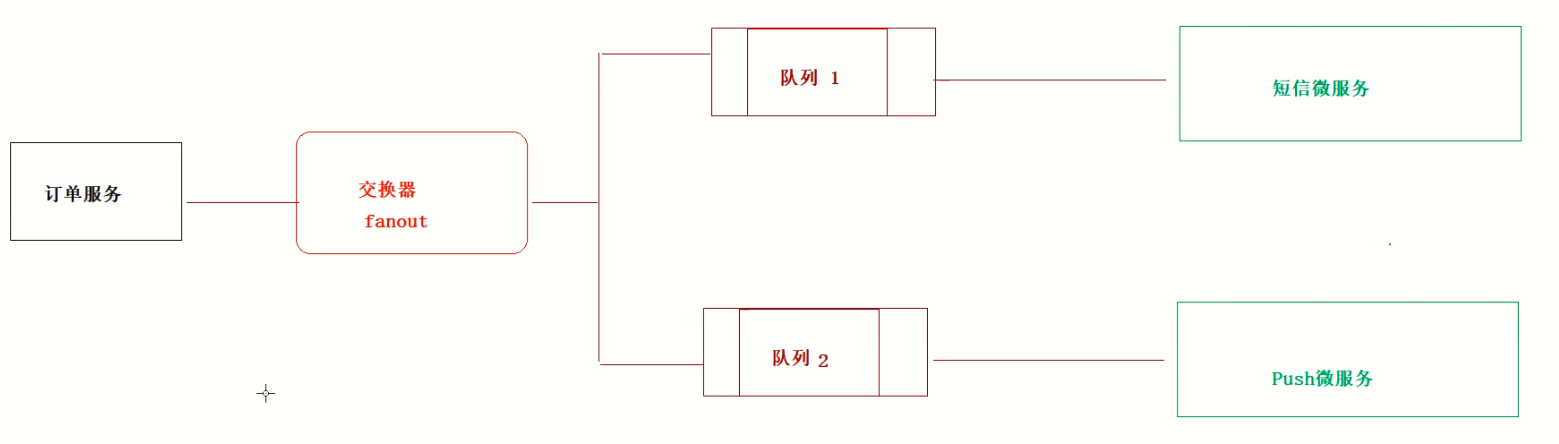
应用场景
以日志系统为例:假设我们定义了一个 Exchange 来接收日志消息,同时定义了两个 Queue 来存储消息:一个记录将被打印到控制台的日志消息;另一个记录将被写入磁盘文件的日志消息。我们希望 Exchange 接收到的每一条消息都会同时被转发到两个 Queue,这种场景下就可以使用 Fanout Exchange 来广播消息到所有绑定的 Queue。
主题规则匹配 topic
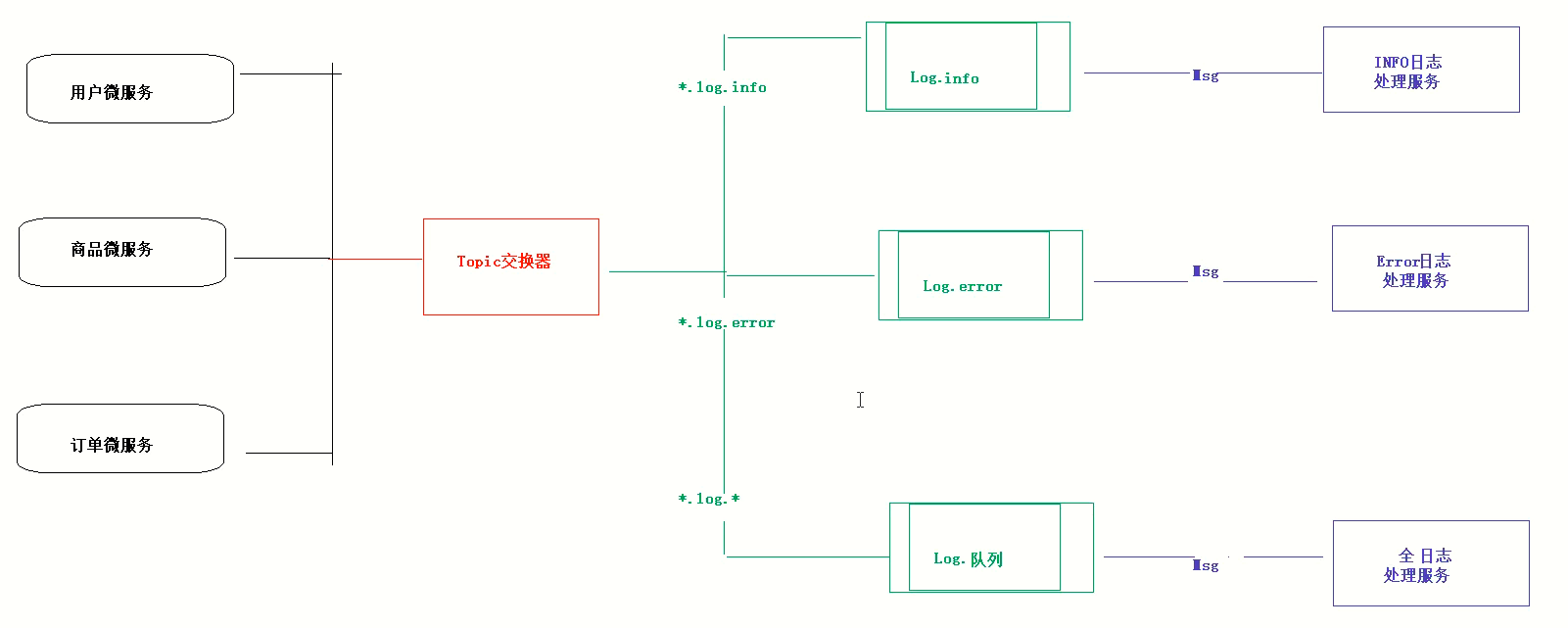
Topic Exchange 和 Direct Exchange 类似,也需要通过 RoutingKey 来路由消息,区别在于Direct Exchange 对 RoutingKey 是精确匹配,而 Topic Exchange 支持模糊匹配。分别支持*和#通配符,*表示匹配一个单词,#则表示匹配没有或者多个单词。
应用场景
假设我们的消息路由规则除了需要根据日志级别来分发之外还需要根据消息来源分发,可以将 RoutingKey 定义为
消息来源.级别如order.info、user.error等。处理所有来源为user的 Queue 就可以通过user.*绑定到 Topic Exchange 上,而处理所有日志级别为info的 Queue 可以通过*.info绑定到 Exchange上。
Rabbit高级
Rabbit 消息持久化
如果我们希望即使在RabbitMQ服务重启的情况下,也不会丢失消息,我们可以将Queue与Message都设置为可持久化的(durable),这样可以保证绝大部分情况下我们的RabbitMQ消息不会丢失。当然还是会有一些小概率事件会导致消息丢失。



